
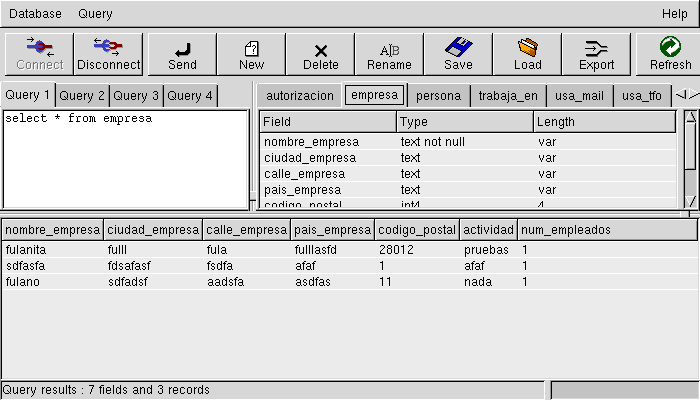
Este artículo es el primero de una serie que pretende enseñar al lector como, con herramientas sobre GNU/Linux se pueden unir dos tecnologías tan importantes hoy en día como son las Bases de Datos y el fenómeno de Internet, en particular la World Wide Web.
En primer lugar se va a realizar una introducción breve a estas tecnologías y a explicar la razón de usar como herramienta de desarrollo e integración a GNU/Linux. Posteriormente se analizarán las herramientas que pueden servir para gestionar la base de datos, y se aplicarán todos los conceptos en el diseño de una aplicación real. Se verán los métodos de programación y las alternativas existentes actualmente para integrar ambos sistemas, deteniéndonos en una de ellas para solucionar la implementación de la aplicación.
La tecnología de bases de datos es una de las más antiguas dentro de la ciencia de la informática, esencialmente es una tecnología que se basa en la capacidad para almacenar y recuperar información relacionada entre sí. Una base de datos puede ser desde un fichero de texto (estilo /etc/passwd) hasta un conjunto de tablas repartidas en ficheros binarios y que acumulen millones de registros. En cualquier caso es necesario un programa capaz de gestionar estos datos y permitir acceder a esta información de la manera más rápida posible.
Existe más de un esquema a la hora del desarrollo y definición de las bases de datos: bases de datos orientadas a objetos, bases de datos relacionales, bases de datos jerárquicas, etc... Hoy en día, a pesar del crecimiento de la programación orientada a objetos y, por tanto, de las bases de datos diseñadas con la misma filosofía (que actualmente permiten el desarrollo de las bases de datos multimedia), el tipo de bases de datos más utilizada sigue siendo las bases de datos relacionales.
Es necesario distinguir en una base de datos su diseño de su implementación, como veremos más adelante, para el mismo diseño se pueden escoger implementaciones distintas que se ajusten más o menos a éste. Evidentemente, si se escoge una implementación inadecuada se perderán algunas de las ventajas del modelo realizado en la etapa de diseño.
Las bases de datos constituyen una importante herramienta a la hora de almacenar y recuperar la información. Sin embargo, para utilizar esta herramienta es necesario ofrecer un interfaz al usuario para abstraer toda su complejidad. Sin este interfaz la base de datos puede seguir utilizándose pero el usuario ha de conocer el "lenguaje" de la misma para hacer uso de ésta (actualmente el más utilizado es SQL, Standard Query Language).
Así pues, el interfaz es un elemento fundamental a la hora de hacer uso de una base de datos, aquí es donde entra la World Wide Web (WWW).
La World Wide Web se puede considerar como el elemento de Internet que integra el cliente universal, y por tanto, puede usarse como el interfaz universal a todo tipo de aplicaciones.
Muchos fabricantes de equipos y desarrolladores han empezado a mover sus aplicaciones e interfaces para que puedan ser operados con clientes basados en ésta. Así, por ejemplo, nos encontramos con fabricantes de elementos de interconexión de redes (switches, conmutadores, o routers) o impresoras de red que incluyen en su hardware un servidor de WWW para que sus herramientas puedan ser manejadas, configuradas, en fin, gestionadas, desde un navegador de WWW.
La ventaja para el fabricante es clara ya que le evita tener que crear una herramienta para el cliente, ahorrando en el desarrollo; no olvidemos que para un fabricante de hardware un cliente puede ser, potencialmente, cualquier combinación posible de uso de hardware, sistema operativo y software. Así pues en lugar de tener que realizar un interfaz para, por ejemplo, Solaris, otro para Linux y otro para Windows NT, el fabricante indica al usuario que sólo necesita un navegador de WWW como interfaz a la gestión de su equipo. No será necesario que programe un interfaz para cada plataforma en la que quiera que su hardware sea gestionado sino que, al incorporar tecnologías estándar de la WWW tanto de presentación (HTML) como de interacción cliente servidor (protocolo HTTP) su herramienta puede ser utilizada desde cualquier lugar y con cualquier plataforma que tenga un cliente de WWW.
El movimiento del acceso de bases de datos de sistemas propietarios a un sistema abierto como es la WWW, empezó ya hace años, y su arquetipo un sistema por y para la WWW, es el conocido yahoo, en realidad cualquier buscador en la WWW. Este buscador no es más que una base de datos de documentos al que se accede mediante un interfaz WWW. La ventaja, al margen de la que ofrezca la aplicación en si, es que, por un lado, cualquiera puede "preguntar" a la base de datos sin conocer el funcionamiento de lo que hay detrás, por otro los "clientes" potenciales son todos aquellos con acceso a la WWW porque los estándares usados son los mismos que para acceder a cualquier otro servidor.
GNU/Linux es un sistema ideal para instalar una base de datos que se va a utilizar desde Internet, no sólo por su demostrada velocidad en el acceso a bases de datos, sino también por la multitud de sistemas de bases de datos y herramientas que se pueden encontrar para GNU/Linux.
En GNU/Linux se dispone actualmente de un buen número de sistemas de bases de datos, por un lado sistemas libres como PostgreSQL o BeagleSQL, por otro sistemas "semi-libres" como mSQL o mySQL, y, finalmente, sistemas propietarios: Oracle, Informix o Sybase.
También dispone de una multitud de servidores de WWW, de entre los que merece una mención especial Apache, el servidor de WWW más utilizado en Internet. Finalmente, al tratarse de un sistema abierto y poderse optimizar "a medida" para el desarrollo a realizar se convierte en la alternativa ideal.
No hay que olvidar tampoco el factor coste. En la actualidad se puede montar un sistema profesional utilizando herramientas totalmente libres, el coste será sólo el del hardware y el de las personas dedicadas a montarlo. El coste en licencias será nulo y puede creer el lector que el coste de un sistema de base de datos y un sistema operativo propietarios que dé las mismas prestaciones (sino menos) es ciertamente elevado (estamos hablando de millones de pesetas). Si se monta el sistema con herramientas libres se podrán adaptar al 100% para lo que se precisa ya que el desarrollador tendrá a su disposición el código fuente de todas ellas para adaptarlas a medida.
Para montar un sistema de interfaz de bases de datos vía WWW se han elegido como componentes básicos:
Gracias al sistema de paquetes usado por las distribuciones de
GNU/Linux, hoy en día se pueden instalar los componentes comentados
previamente sin mayor esfuerzo por parte del
administrador. Simplemente seleccionando el componente e instalándolo,
restando sólo hacer la configuración (que en la mayor parte de los
casos vendrá una por defecto pero será necesaria adaptar a las necesidades
específicas del usuario). En el caso de Debian GNU/Linux instalaremos
los paquetes apache y postgresql.
Podríamos comentar cómo hacer la instalación a partir de cero desde el código fuente distribuido por los proyectos de desarrollo, pero no se va a comentar aquí como hacerlo ya que ha sido previamente comentado para ambos componentes en esta misma revista.
Dado que aún no hemos especificado la aplicación que vamos a realizar no entraremos aún en la configuración de estos componentes, sino que la dejaremos para más adelante. Nos bastará con ver que los componentes han sido correctamente instalados y funcionan.
Para ver que efectivamente tenemos el servidor de web instalado y lanzado haremos lo siguiente:
ps aux |
grep apache. Que nos deberá mostrar el proceso ejecutándose. Si
no aparece una lista de procesos lo deberíamos reiniciar con
/etc/init.d/apache start (esto es para Debian GNU/Linux,
otras distribuciones ponen los guiones para lanzar los demonios de
otra forma.telnet localhost 80 y ver
que efectivamente hay una conexión. Para cerrarla sin enviar
pulsaremos Ctrl+5 lo que enviará el código de escape a la aplicación
telnet y podremos cerrarla escribiendo close (más
información man telnet)http://localhost/. Si el servidor ha sido adecuadamente
lanzado veremos una página de muestra.En cualquier caso si vemos cualquier problema es recomendable acudir a
la documentación. En el caso de Debian viene dentro del paquete
apache-doc, y que, tras instalar, incluirá la documentación
en /usr/doc/apache-doc. También es recomendable acudir a los
registros del programa que se encuentran (en Debian) en
/var/log/apache.
Para probar la configuración de PostgreSQL vamos a utilizar uno de los interfaces de gestión que más adelante se comentarán, ya que se trata del más sencillo viene incluido con la distribución normal de PostgreSQL.
Conviene comentar que Debian GNU/Linux viene con un usuario de gestión de la base de datos que es que el debe usarse para realizar la gestión de la misma: creación de usuarios de la base de datos y bases de datos. Mientras no se haya creado ningún usuario de base de datos que sea un DBA (Database Administrator) será necesario usar siempre éste.
Por ello para probar la base de datos lo primero que haremos será
"convertirnos" en este usuario haciendo, como superusuario, su -
postgres. Este usuario tiene como directorio home el
/var/postgres que es donde se van a encontrar todos los
ficheros que utilice la base de datos. Tras esto haremos algunas
pruebas:
ps aux
|grep postgres que nos deberá listar un proceso lanzado como
usuario postgres. Si no es así quizás no esté lanzado (aunque el
gestor de paquetes lo lanza al instalarlo) pero se puede lanzar con
/etc/init.d/postgres start./etc/services), y
podríamos probarlo conectándonos mediante un telnet como antes.pgsql sin argumentos. Si nos da un
prompt del estilo de template1=> estará
funcionando correctamente (saldremos con Ctrl+D o con "\q"). Si da un
error posiblemente no esté funcionando.De la misma forma que Apache, para cualquier problema debemos
consultar la documentación, que en Debian se instala en el paquete
postgres-doc, y los ficheros de registro que ahora estarán en
/var/log/postgres.log.
Hay ciertas herramientas de gestión de la base de datos que son
necesarias conocer para utilizarlas como usuario 'postgres'. Veremos
más adelante su uso particular para la base de datos que se va a
crear, pero no está de más recordarlas aquí. Al instalar la
distribución de postgres, quedarán instalados en el directorio
/usr/lib/postgresql/bin los programas que son necesarios para
gestionar "desde cero" la base de datos. Estos programas estarán en el
PATH del usuario postgres.
Antes de nada es necesario tener clara una cosa del sistema de base de
datos. Un sistema de base de datos es una colección de bases de datos
administradas por el mismo usuario, físicamente el sistema así como
cada base de datos, es una serie de ficheros pertenecientes al usuario
y que el servicio postmaster se encarga de gestionar, en el
caso de Debian estos ficheros se instalan por defecto en
/var/lib/postgres/data. La ventaja de esta filosofía es que
para mover la base de datos o hacer una copia de seguridad de ésta
basta con copiar los ficheros de la misma.
cleardbdir: destruye todas las bases de datos
instaladas. Sólo se utiliza cuando se quiere reinicializara el sistema
de base de datos y es necesario para el demonio postmaster.
initdb: crea un nuevo sistema de base de datos, crea
los directorios necesarios para el sistema y la base de datos
template1 que se trata de la plantilla a través de la cual
se generarán el resto de las bases de datos. En un sistema en el que
se haya instalado correctamente la base de datos esto se habrá
realizado ya y el usuario no tendrá que hacerlo.
initlocation: prepara un directorio para albergar el
sistema de base de datos.
pg_passwd: permite manipular el fichero de contraseñas
de la base de datos. Se trata de una aplicación similar al programa
passwd pero para el sistema de base de datos.
pg_upgrade: permite actualizar el sistema de base de
datos. Cuando se cambia de versión del sistema de base de datos es
necesario actualizar los datos ya que sino serán incompatibles con el
nuevo sistema. Este programa facilita el movimiento de una versión a otra.
pg_dump y pg_dumpall vuelcan (una base de
datos en el caso del primero y todas las bases el segundo), las
ordenes SQL necesarias en un fichero ASCII de forma que la base de
datos se pueda recuperar a través de éste. Sin hacer uso de ninguna
opción la base de datos será volcada con todos los datos incluidos. Al
tratarse de SQL estándar, este mismo fichero puede usarse para crear
de nuevo la base de datos en otro sistema de bases de datos,
facilitando la migración a cualquier otro sistema.
pg_id: devuelve el identificador de usuario
correspondiente al usuario administrador de las bases de datos.
createdb: crea una base de datos en nuestro sistema de
base de datos. En realidad llama al interfaz pgsql para
realizar esto.
createuser: crea un usuario reconocido en el sistema de
bases de datos. Los usuarios del sistema de base de datosno
tienen por qué tener relación con los usuarios en nuestro sistema
operativo, pudiendo haber usuarios distintos.
destroydb: elimina una base de datos.
destroyuser: elimina un usuario del sistema de bases de
datos.
El administrador de la base de datos necesita conocer estas herramientas para usarlas, si surge la necesidad. En particular, aquellas funciones que no se pueden hacer a través del interfaz, ya que la creación y destrucción de bases de datos y usuarios se podrá hacer con las herramientas de gestión que ahora se analizarán.
Antes de hacer nada en el sistema de base de datos, ni crear usuarios ni otras bases de datos, deberemos conocer primero qué programas podremos usar para la gestión de la base de datos:
pgsql: el interfaz en modo texto para acceder a la base
de datos, permite realizar todas las funciones de acceso a una base de
datos mediante órdenes SQL (teclear \h para acceder a la lista
de todas las órdenes disponibles) y obtener también información del
sistema de base de datos, como ver las bases de datos, los tipos de
datos soportados, etc... para ver las órdenes disponibles teclear
\?.
pgaccess (última versión 0.98.4): interfaz en Tcl/Tk que permite visualizar las
tablas, crearlas mediante un formulario de forma rápida, etc.. Es el
interfaz más evolucionado para postgresql aparte del interfaz
textual. No son necesarios conocimientos de SQL para hacer uso de
muchas de las funciones y permite administrar tanto la base de datos
como los datos en sí de una manera eficaz. En el caso de Debian para
instalarlo es necesario instalar el paquete libpgtcl.
gtksql (última versión 0.3): interfaz en Gtk a la base
de datos. Muestra las tablas de la base de datos y permite hacer
consultas SQL, visualizando el resultado en el mismo interfaz. Se
trata de una herramienta aún en desarrollo pero que le puede resultar
útil a un administrador para hacer tareas sencillas.
gasql: un interfaz en Gtk para PostgreSQL desarrollado
para el proyecto GNOME, aún se encuentra en desarrollo, pero tiene
algunas funcionalidades útiles.Estos programas nos van a ser útiles para poder acceder a la base de
datos sin tener muchos conocimientos del funcionamiento de ésta,
aunque nos va a ser imprescindible el conocimiento del lenguaje SQL,
podemos utilizarlas en muchas situaciones. Existen otras herramientas
como wisql y owd que el autor aún no ha probado, y
serán comentadas en posteriores artículos.
En los siguientes artículos de esta serie vamos a analizar el desarrollo de una aplicación específica y a ver las herramientas necesarias para ofrecer un interfaz de acceso a nuestra base de datos mediante la WWW.
Llevaremos a cabo el análisis de la aplicación así como su desarrollo y empezaremos a ver la ventaja de tener herramientas gráficas de gestión de la base de datos para detectar errores y depurar la aplicación.
LISTADO 1-
Para el lector interesado se recomienda buscar más información en diversos servidores de web. Estos son:
/usr/doc/HOWTO al instalar el paquete
HOWTO en Debian.También para seguir esta serie puede ser conveniente algún conocimiento de bases de datos generales. Se recomienda el libro de Silberschatz, Korth y Sudarsan: "Database Systems Concepts, III ed, Mc Graw-Hill, 1996." ( http://www.bell-labs.com/topic/books/db-book/index.html) que también ha sido traducido al castellano, otro libro también recomendado es el de Ullman y Widom: "A First Course in Database Systems" de 1997 editado por Prentice-Hall ( http://www-db.stanford.edu/~ullman/fcdb.html).
Para el lector que quiera profundizar en SQL podrá encontrar muchos enlaces en la parte bibliográfica del HOWTO de PostgreSQL para Linux aunque también es recomendable el tutorial disponible en http://w3.one.net/~jhoffman/sqltut.htm.
Finalmente, se recomienda la lectura de los artículos relacionados con Bases de Datos publicados en Linux Actual ("Bases de Datos en Internet bajo GNU/Linux" de Alvaro del Castillo en LA 2 y la serie "ODBC sobre Linux" de Juan Antonio Martínez que comienza en LA 3 ) y en Linux Journal (número 5 de la edición en castellano "Especial Bases de Datos").
PIE LISTADO 1:Servidores donde encontrar más información
Esta es la lista de ficheros adjuntos así como su pie de página. La primera captura puede ir en cualquier lado, las segundas conviene que estén hacia el final del artículo.
Es mejor que, si no entra todo el artículo, antes que ponerlo a cuatro columnas se avise al autor de que es necesario recotarlo. Dado que es una serie no hay ningún problema en poner lo recortado en el siguiente artículo de la serie. Por favor, contactar con el autor si hay algún problema.
Este es el primer artículo de la serie, si es necesario recortarlo hablar con el autor para que lo que no se incluya en éste número se incluya en el siguiente artículo.