 |
Ha llevado años implementarlos, por tanto a lo largo de la historia ha habido todo tipo de ideas para intentar hacerlos lo más eficientes posible. En este documento se estudian unas cuantas de estas implementaciones (PVM, MPI, Beowulf) y se ahondará en una de ellas: openMosix.
La primera división en las implementaciones puede ser la división entre
las
Esto tiene bastantes inconvenientes: muchas de las aplicaciones que necesitan grandes tiempos de cómputo se realizaron hace décadas en lenguaje Fortran. Este lenguaje aparte de estar relegado hoy en día a aplicaciones matemáticas o físicas, puede llegar a ser bastante difícil de comprender; por lo tanto es bastante difícil migrarlo al nuevo entorno distribuido.
Por otro lado una de las ventajas que tienen los clusters HP con respecto a los supercomputadores es que son bastante más económicos. Pero si el dinero que se ahorra en el hardware hay que invertirlo en cambiar los programas esta solución no aporta beneficios que justifiquen tal migración de equipos. Además hay que tener en cuenta que la mayor parte de las instituciones o instalaciones domésticas no tienen dinero para invertir en ese software, pero que sí disponen de ordenadores en una red (universidades por ejemplo) .
La segunda opción es que el software que se encarga del HP se encuentre en el kernel del sistema operativo. En este caso no se necesitan cambiar las aplicaciones de usuario, sino que éstas usan las llamadas estándar del kernel por lo tanto el kernel internamente es el que se encarga de distribuir el trabajo de forma transparente a dicha aplicación. Esto tiene la ventaja de que no hace falta hacer un desembolso en cambiar las aplicaciones que lo necesitan y que cualquier aplicación puede ser distribuida. Por supuesto un factor que siempre habrá que tener en cuenta es la propia programación de la aplicación.
Por otro lado esta aproximación también tiene varios inconvenientes: el kernel se vuelve mucho más complejo y es más propenso a fallos. También hay que tener en cuenta que estas soluciones son específicas de un kernel, por lo que si las aplicaciones no están pensadas para ese sistema operativo habría que portarlas. Si los sistemas operativos tienen las mismas llamadas al sistema, siguiendo un estándar POSIX, no habría grandes problemas. Otros sistemas operativos propietarios que no cumplen estos estándares no pueden disponer de estas ventajas.
Una forma de conseguir HP es migrando procesos, dividiendo las aplicaciones grandes en procesos y ejecutando cada proceso en un nodo distinto. Lo que se quiere conseguir es el máximo uso de los recursos en todo momento, especialmente los procesadores. Para conseguirlo hay dos aproximaciones:
En esta aproximación es importantísima la política de localización. Se elige estáticamente el nodo donde el proceso vivirá toda su vida. Por tanto es muy importante elegir correctamente estos nodos. Muchas veces esta solución necesita un administrador que decida dónde debe ir cada proceso. El caso más simple es tener todos los nodos con la misma potencia de cálculo y dividir el único programa al que se quiera dedicar los recursos en un número de procesos igual al número de nodos de los que se disponen. Asíse asignaría cada proceso a uno de los nodos. Hay que tener en cuenta que esta configuración es lejana a la normal y que ya que un fallo en el algoritmo de elección de nodo puede infrautilizar mucho de los recursos la configuración manual es normal en estos algoritmos. Esto no es tan malo como pueda parecer a primera vista porque es también muy corriente en estos casos que una vez hecha la configuración inicial, los procesos estén ejecutándose durante años si es necesario.
Los procesos una vez iniciados en un nodo pueden migrar a otro nodo dinámicamente. En estos casos aunque es importante la política de localización para minimizar el gasto de recursos, también es importantísima la política de migración. Por supuesto también se pueden ubicar los procesos manualmente, con la ventaja de que se pueden ubicar en cualquier momento durante la vida del proceso. Si la política de migración es correcta y los procesos tienen una vida larga y se ha dividido correctamente la aplicación, debería haber al comienzo de la ejecución de los procesos un periodo de reordenación de los procesos, con varias migraciones, una vez el sistema llegara a una condición estable, no deberían producirse apenas migraciones hasta que los procesos finalizaran. Igual que ocurre en el caso anterior, esta configuración es lejana a la habitual, pero al contrario del caso anterior, aquíno es necesaria la configuración manual (si el algoritmo de migración es suficientemente bueno). Cuando se desbalancea el sistema éste se encarga de que se vuelva a balancear, de tal forma de que se aprovechen los recursos al máximo.
Como ya se verá con más detalle, openMosix intenta maximizar el uso de todos los recursos. Intentar solamente balancear respecto al procesador puede dar lugar a decisiones bastante malas, porque se pueden enviar muchos procesos que no hagan mucho uso del procesador a uno de los nodos, si estos procesos están haciendo entrada/salida y son procesos grandes, es muy posible que el nodo empiece a hacer trashing pues se quedará sin memoria, con lo que los procesos no podrán ejecutar su función.
En el cuadro se aprecian las posibles formas que existen para clusters.
Se muestra este cuadro para que se pueda comprender la cantidad de decisiones
que se tienen que hacer cuando se implementa un cluster de este tipo y
asíse comprenderá mejor por qué hay tantas implementaciones
y tan dispares.
|
Requisa se refiere a poder parar el proceso y coger sus recursos (básicamente los registros del procesador y memoria). La requisa de los procesos puede existir o no. Con requisa no queremos decir hacer requisa de los procesos para migrarlos después, sino simplemente poder hacer requisa de un proceso en cualquier momento. Cuando un sistema es multitarea normalmente se implementa algún sistema de requisa para poder parar procesos y hacer que otros procesos tomen el procesador para dar la sensación al usuario de que todos los procesos se están ejecutando concurrentemente.
Si no se implementa requisa, un proceso de baja prioridad puede tomar el procesador y otro proceso de alta prioridad no podrá tomarlo hasta que el proceso de baja prioridad lo ceda a otros procesos. Este esquema puede ser injusto con las prioridades y un error en un programa, puede llegar a dejar sin funcionar la máquina pues nunca devolvería el control, pero tampoco haría ningún trabajo útil. Además para sistemas que necesitan tiempo real, simplemente es inaceptable que procesos de baja prioridad estén dejando a los procesos de tiempo real sin tiempo de procesador y quizás con esta latencia extra se esté haciendo que el sistema no pueda cumplir sus operaciones en tiempo real, haciendo que el sistema sea inútil. Hoy en día la requisa se implementa al menos a un nivel elemental en casi todos los sistemas que necesiten hacer funcionar más de un proceso (por no decir todos). Algunos sistemas lo que hacen es no esperar a que cumpla un temporizador y realizar la requisa sino a esperar que el proceso haga alguna llamada al sistema para aprovechar, tomar el procesador y cederlo a otro proceso. Esta aproximación sigue teniendo el problema de que si un proceso maligno o mal programado no hace llamadas a sistema porque haya quedado en un bucle, nunca se ejecutará nada en ese ambiente.
Si se implementa la requisa hay que tener en cuenta que la implementación más simple que se puede dar (que es la que usan buena parte de los sistemas) necesita un temporizador que marque cuando se acabó el tiempo del proceso y requisar ese proceso para asignar a otro proceso. Esto impone una sobre carga pues hay que tratar una interrupción, actualizar unas variables para saber cuanto tiempo lleva un proceso trabajando.
Hay una implementación más compleja que trata de que siempre que haya un proceso de una prioridad mayor al que se está ejecutando se quite el procesador al proceso y se dé el procesador al proceso con mayor prioridad. Estos suelen ser sistemas en tiempo real que también (ya que se ponen) pueden tener otras exigencias como unos tiempos mínimos de latencia para ciertos procesos. Para conseguir esto, el kernel no solamente tiene que requisar procesos de baja prioridad en favor de los procesos de tiempo real sino que tiene que ser capaz de requisar su propio código. Esto suele significar que casi cualquier porción del código del kernel se puede ejecutar entre dos instrucciones de este mismo código. Esto presenta muchísimos problemas a la hora de programar, hay que tener mucho más cuidado con evitar condiciones de carrera dentro del propio kernel que antes por ser código no requisable no se podían dar. Por tanto implementar requisa, puede hacer que un sistema sea tiempo real pero complica tremendamente el núcleo del sistema.
Las siguientes tres líneas en el cuadro tratan sobre los recursos del cluster, estos son los nodos. Existen tres modos en los que se puede dedicar los nodos del cluster, estos modos son:
En este modo que es el más simple de todos, solamente un trabajo está siendo ejecutado en el cluster en un tiempo dado, y como mucho un proceso de este trabajo que se está ejecutando es asignado a un nodo en cualquier momento en el que se siga ejecutando el trabajo. Este trabajo no liberará el cluster hasta que acabe completamente aunque solamente quede un proceso ejecutándose en un único nodo. Todos los recursos se dedican a este trabajo, como se puede comprender fácilmente esta forma de uso de un cluster puede llevar a una pérdida importante de potencia sobre todo si no todos los nodos acaban el trabajo al mismo tiempo.
En este modo, varios trabajos pueden estar ejecutándose en particiones disjuntas del cluster que no son más que grupos de nodos. Otra vez como mucho un proceso puede estar asignado a un cluster en un momento dado. Las particiones están dedicadas a un trabajo, la interconexión y el sistema de entrada/salida puede estar compartidos por todos los trabajos, consiguiendo un mejor aprovechamiento de los recursos. Los grupos de nodos son estáticos y los programas necesitan un número específico de nodos para poder ejecutarse, esto lleva a dos conclusiones:
En cada nodo pueden estar ejecutándose varios procesos a la vez por lo que se solucionan los problemas anteriores. Este es el modo más usado normalmente puesto que no tiene tantas restricciones como el otro y se puede intentar hacer un equilibrado de carga eligiendo correctamente los procesos.
Hay dos tipos de scheduling en cuanto a clusters se refiere:
Es el caso más sencillo y más implementado, se usa un sistema operativo en cada nodo del cluster para hacer scheduling de los distintos procesos en un nodo tradicional, esto también es llamado scheduling local. Sin embargo, el rendimiento de los trabajos paralelos que esté llevando a cabo el cluster puede verse degradado en gran medida.
Cuando uno de los procesos del trabajo paralelo quiera hacer cualquier tipo de interacción con otro proceso por ejemplo sincronizarse con él, este proceso puede que no esté ejecutándose en esos momentos y puede que aún se tarde un tiempo (dependiente normalmente de su prioridad) hasta que se le ejecute por otro cuanto de tiempo. Esto quiere decir que el primer proceso tendrá que esperar y cuando el segundo proceso esté listo para interactuar quizás el primer proceso esté en swap y tenga que esperar a ser elegido otra vez para funcionar.
En este tipo se hace scheduling sobre todos los procesos del trabajo a la vez. Cuando uno de los procesos está activo, todos los procesos están activos. Estudios4.17 han demostrado que este tipo de scheduling puede aumentar el rendimiento en uno o dos puntos de magnitud. Los nodos del cluster no están perféctamente sincronizados. De hecho, la mayoría de los clusters son sistemas asíncronos, que no usan el mismo reloj.
Cuando decimos, a todos los procesos se le hace scheduling a la vez, no quiere decir que sea exáctamene a la vez. Según ese mismo estudio, según aumenta la diferencia entre que se elige para ejecutarse el primer proceso y el último, se pierda rendimiento (se tarda más en acabar el trabajo). Para conseguir buenos rendimientos se tiene que o bien, permitir a los procesos funcionar por mucho tiempo de forma continuada o bien que la diferencia entre que un proceso se ejecuta y el ultimo se ejecuta es muy pequeña.
Pero como se puede comprender, hacer scheduling en un cluster grande, siendo el scheduling una operación crítica y que tiene que estar optimizada al máximo es una operación bastante compleja de lograr, además se necesita la información de los nodos para poder tomar buenas decisiones, lo que acaba necesitando redes rápidas.
Cuando un proceso P ejecuta un envío síncrono a un proceso Q, tiene que esperar hasta que el proceso Q ejecuta el correspondiente recibo de información síncrono. Ambos procesos no volverán del envío o el recibo hasta que el mensaje está a la vez enviado y recibido.
Cuando el enviar y recibir acaban, el mensaje original puede ser inmediatamente sobrescrito por el nuevo mensaje de vuelta y éste puede ser inmediatamente leído por el proceso que envió originariamente el mensaje. No se necesita un buffer extra en el mismo buffer donde se encuentra el mensaje de ida, se escribe el mensaje de vuelta.
Un envío bloqueante es ejecutado cuando un proceso lo alcanza sin esperar el recibo correspondiente. Esta llamada bloquea hasta que el mensaje es efectivamente enviado, lo que significa que el mensaje (el buffer donde se encuentra el mensaje) puede ser reescrito sin problemas. Cuando la operación de enviar ha acabado no es necesario que se haya ejecutado una operación de recibir. Sólo sabemos que el mensaje fue enviado, puede haber sido recibido o puede estar en un buffer del nodo que lo envía, o en un buffer de algún lugar de la red de comunicaciones o puede que esté en el buffer del nodo receptor.
Un recibo bloqueante es ejecutado cuando un proceso lo alcanza, sin esperar a su correspondiente envío. Sin embargo no puede acabar sin recibir un mensaje. Quizás el sistema esté proveyendo un buffer temporal para los mensajes.
Un envío no bloqueante es ejecutado cuando un proceso lo alcanza, sin esperar al recibo. Puede acabar inmediatamente tras notificar al sistema que debe enviar el mensaje. Los datos del mensaje no están necesariamente fuera del buffer del mensaje, por lo que es posible incurrir en error si se sobreescriben los datos.
Un recibo no bloqueante es ejecutado cuando un proceso lo alcanza, sin esperar el envío. Puede volver inmediatamente tras notificar al sistema que hay un mensaje que se debe recibir. El mensaje puede que no haya llegado aún, puede estar todavía en transito o puede no haber sido enviado aún.
El modelo en el que se basa PVM es dividir las aplicaciones en distintas tareas (igual que ocurre con openMosix). Son los procesos los que se dividen por las máquinas para aprovechar todos los recursos. Cada tarea es responsable de una parte de la carga que conlleva esa aplicacion. PVM soporta tanto paralelismo en datos, como funcional o una mezcla de ambos.
PVM permite que las tareas se comuniquen y sincronicen con las demás tareas de la máquina virtual, enviando y recibiendo mensajes, muchas tareas de una aplicación pueden cooperar para resolver un problema en paralelo. Cada tarea puede enviar un mensaje a cualquiera de las otras tareas, sin límite de tamaño ni de número de mensajes.
El sistema PVM se compone de dos partes. La primera es un demonio, llamado pvmd que residen en todas los nodos que forman parte de la máquina virtual. Cuando un usuario quiere ejecutar una aplicación PVM, primero crea una máquina virtual para arrancar PVM. Entonces se puede ejecutar la aplicación PVM en cualquiera de los nodos. Muchos usuarios pueden configurar varias máquinas virtuales aunque se mezclen unas con las otras y se pueden ejecutar varias aplicaciones PVM simultáneamente. Cada demonio es responsable de todas las aplicaciones que se ejecutan en su nodo.
Asíel control está totalmente distribuido excepto por un demonio maestro, que es el primero que se ejecuto a mano por el usuario, los demás nodos fueron iniciados por el maestro y son esclavos. En todo momento siempre hay un pvmd maestro. Por tanto la máquina virtual mínima es de un miembro, el maestro.
La segunda parte del sistema es la librería de PVM. Contiene un repertorio de primitivas que son necesarias para la cooperación entre los procesos o threads de una aplicación. Esta librería contiene rutinas para inicialización y terminación de tareas, envío y recepción de mensajes, coordinar y sincronizar tareas, broadcast, modificar la máquina virtual.
Cuando un usuario define un conjunto de nodos, PVM abstrae toda la complejidad que tenga el sistema y toda esa complejidad se ve como un gran computador de memoria distribuida llamada máquina virtual. Esta máquina virtual es creada por el usuario cuando se comienza la operación. Es un conjunto de nodos elegidos por el usuario. En cualquier momento durante la operación puede elegir nuevos nodos para la máquina virtual. Esto puede ser de gran ayuda para mejorar la tolerancia a fallos pues se tiene unos cuantos nodos de reserva (PVM no tiene migración) para si alguno de los nodos fallara. O si se ve que un conjunto de nodos de una determinada red están fallando se pueden habilitar nodos de otra red para solucionarlo. Para conseguir abstraer toda la complejidad de las diferentes configuraciones, soporta la heterogeneidad de un sistema a tres niveles:
Todas las tareas están identificadas con un único identificador de tarea TID (Task IDentifier). Los mensajes son enviados y recibidos por TIDs. Son únicos en toda la máquina virtual y están determinados por el pvmd local y no se pueden elegir por el usuario. Varias funciones devuelven estos TIDs (pvm_mytid(), pvm_parent(), etc.)para permitir que las aplicaciones de los usuarios conozcan datos de las otras tareas. Existen grupos nombrados por los usuarios, que son agrupaciones lógicas de tareas. Cuando una tarea se une al grupo, a ésta se le asigna un único número dentro de ese grupo. Estos números empiezan en 0 y hasta el número de tareas que disponga el grupo. Cualquier tarea puede unirse o dejar cualquier grupo en cualquier momento sin tener que informar a ninguna otra tarea del grupo. Los grupos se pueden superponer y las tareas pueden enviar mensajes multicast a grupos de los que no son miembro.
Cuando una tarea se quiere comunicar con otra ocurren una serie de cosas,
los datos que la tarea ha enviado con una operación send, son
transferidos a su demonio local quien decodifica el nodo de destino y
transfiere los datos al demonio destino. Este demonio decodifica la
tarea destino y le entrega los datos. Este protocolo necesita 3
transferencias de datos de las cuales solamente una es sobre la red.
También se puede elegir una política de encaminado directo (dependiente
de los recursos disponibles).
En esta política tras la primera comunicación entre dos tareas los datos
sobre el camino a seguir por los datos son guardados en una caché local.
Las siguientes llamadas son hechas directamente gracias a esta información.
De esta manera las transferencias se reduce a una transferencia sobre la
red.
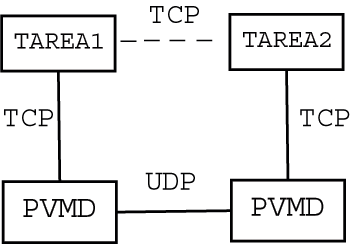
Para comunicar entre sé los demonios pvmd se usa UDP pues es
mucho más sencillo, sólo consume un descriptor de fichero, y con
un simple socket UDP se puede comunicar a todos los demás demonios.
Además es muy sencillo colocar temporizadores sobre UDP para
detectar fallos de nodo, pvmd o red.
La comunicación entre las tareas y los pvmd es mediante TCP
puesto que se necesita tener la seguridad de que los datos llegarán.
En el caso de que sólo se haga una trasferencia ésta es TCP por lo que
hay que establecer la conexión primero por lo que realmente tampoco es
tan beneficioso.
En la siguiente figura se puede observar como los distintos métodos de
comunicación de PVM.
Las aplicaciones pueden ver el hardware como una colección de elementos de proceso virtuales sin atributos o pueden intentar explotar las capacidades de máquinas específicas, intentando posicionar ciertas tareas en los nodos más apropiados para ejecutarlas.
Hemos querido dar un rápido repaso a PVM para poder decir qué es lo que no nos gusta de su aproximación y porque pensamos que openMosix es superior. Sabemos que la explicación que hemos dado está lejos de mostrar todo el universo de PVM pero pensamos que puede dar una idea de cómo funciona.
PVM no tiene requisa de procesos dinámico, esto quiere decir que una vez que un proceso empieza en una determinada máquina seguirá en ella hasta que se muera. Esto tiene graves inconvenientes como explicamos en las características de asignar estáticamente un proceso a un nodo en concreto. Hay que tener en cuenta que las cargas suelen variar y que, a no ser que todos los procesos que se estén ejecutando sean muy homogéneos entre sí, se está descompensando el cluster. Por lo tanto tenemos unos nodos más cargados que otros y seguramente unos nodos terminen su ejecución antes que otros, con lo que se podrían tener nodos muy cargados mientras otros nodos están libres. Esto lleva a una pérdida de rendimiento general.
Otro problema de PVM es que está implementado a nivel de usuario, esto no es malo de por sí pero teniendo en cuenta el tipo de operaciones que lleva, sílo es puesto que son operaciones de bastante bajo nivel como puedan ser paso de mensajes entre aplicaciones y la capa sobre UDP. Esto añade complejidad y latencia a las comunicaciones que se tienen que producir sobre las comunicaciones del kernel. Por lo que es una capa de software extra que carga bastante.
Se necesita un conocimiento amplio del sistema, tanto los programadores como los administradores tienen que conocer el sistema para sacar el máximo rendimiento de él. No existe un programa que se ejecute de forma ideal en cualquier arquitectura ni configuración de cluster. Por lo tanto para paralelizar correcta y eficazmente se necesita que los programadores y administradores conozcan a fondo el sistema.
El paralelismo es explícito, esto quiere decir que se programa de forma especial para poder usar las características especiales de PVM. Los programas deben ser reescritos. Si a esto se unimos que, como se necesita que los desarrolladores estén bien formados por lo explicado en el punto anterior y que conozcan además PVM, se puede decir que migrar una aplicación a un sistema PVM no es nada económico.
Consigue portabilidad proveyendo una librería de paso de mensajes estándar independiente de la plataforma y de dominio público. La especificación de esta librería está en una forma independiente del lenguaje y proporciona funciones para ser usadas con C y Fortran. Abstrae los sistemas operativos y el hardware. Hay implementaciones MPI en casi todas las máquinas y sistemas operativos. Esto significa que un programa paralelo escrito en C o Fortran usando MPI para el paso de mensajes, puede funcionar sin cambios en una gran variedad de hardware y sistemas operativos. Por estas razones MPI ha ganado gran aceptación dentro el mundillo de la computación paralela.
MPI tiene que ser implementado sobre un entorno que se preocupe de el manejo de los procesos y la E/S por ejemplo, puesto que MPI sólo se ocupa de la capa de comunicación por paso de mensajes. Necesita un ambiente de programación paralelo nativo.
Todos los procesos son creados cuando se carga el programa paralelo y están vivos hasta que el programa termina. Hay un grupo de procesos por defecto que consiste en todos esos procesos, identificado por MPI_COMM_WORLD.
Los procesos MPI son procesos como se han considerado tradicionalmente, del tipo pesados, cada proceso tiene su propio espacio de direcciones, por lo que otros procesos no pueden acceder directamente al las variables del espacio de direcciones de otro proceso. La intercomunicación de procesos se hace vía paso de mensajes.
Las desventajas de MPI son las mismas que se han citado en PVM, realmente son desventajas del modelo de paso de mensajes y de la implementación en espacio de usuario. Además aunque es un estándar y debería tener un API estándar, cada una de las implementaciones varía, no en las llamadas sino en el número de llamadas implementadas (MPI tiene unas 200 llamadas). Esto hace que en la práctica los diseñadores del sistema y los programadores tengan que conocer el sistema particular de MPI para sacar el máximo rendimiento. Además como sólo especifica el método de paso de mensajes, el resto del entorno puede ser totalmente distinto en cada implementación con lo que otra vez se impide esa portabilidad que teóricamente tiene.
Existen implementaciones fuera del estándar que son tolerantes a fallos, no son versiones demasiado populares porque causan mucha sobrecarga.
Entre las posibilidades que integra este proyecto se encuentra la posibilidad de que algunos equipos no necesiten discos duros, por eso se consideran que no son un cluster de estaciones de trabajo, sino que dicen que pueden introducir nodos heterogéneos. Esta posibilidad la da otro programa y Beowulf lo añade a su distribución.
Beowulf puede verse como un empaquetado de PVM/MPI junto con más software para facilitar el día a día del cluster pero no aporta realmente nada nuevo con respecto a tecnología.
Los algoritmos de openMosix son dinámicos lo que contrasta y es una fuerte ventaja frente a los algoritmos estáticos de PVM/MPI, responden a las variaciones en el uso de los recursos entre los nodos migrando procesos de un nodo a otro, con requisa y de forma transparente para el proceso, para balancear la carga y para evitar falta de memoria en un nodo.
Los fuentes de openMosix han sido desarrollados 7 veces para distintas versiones de Unix y BSD, nosotros en este proyecto siempre hablaremos de la séptima implementación que es la que se está llevando a cabo para Linux.
OpenMosix, al contrario que PVM/MPI, no necesita una adaptación de la aplicación ni siquiera que el usuario sepa nada sobre el cluster. Como se ha visto, para tomar ventaja con PVM/MPI hay que programar con sus librerías, por tanto hay que rehacer todo el código que haya (para aprovechar el cluster).
En la sección de PVM ya se han explicado las desventajas que tenía esta aproximación. Por otro lado openMosix puede balancear una única aplicación si esta está dividida en procesos lo que ocurre en gran número de aplicaciones hoy en día. Y también puede balancear las aplicaciones entre sí, lo que balancea openMosix son procesos, es la mínima unidad de balanceo. Cuando un nodo está muy cargado por sus procesos y otro no, se migran procesos del primer nodo al segundo. Con lo que openMosix se puede usar con todo el software actual si bien la división en procesos ayuda al balanceo gran cantidad del software de gran carga ya dispone de esta división.
El usuario en PVM/MPI tiene que crear la máquina virtual decidiendo qué nodos del cluster usar para correr sus aplicaciones cada vez que las arranca y se debe conocer bastante bien la topología y características del cluster en general. Sin embargo en openMosix una vez que el administrador del sistema que es quien realmente conoce el sistema, lo ha instalado, cada usuario puede ejecutar sus aplicaciones y seguramente no descubra que se está balanceando la carga, simplemente verá que sus aplicaciones acabaron en un tiempo record.
PVM/MPI usa una adaptación inicial fija de los procesos a unos ciertos nodos, a veces considerando la carga pero ignorando la disponibilidad de otros recursos como puedan ser la memoria libre y la sobrecarga en dispositivos E/S.
En la práctica el problema de alojar recursos es mucho más complejo de lo que parece a primera vista y de como lo consideran estos proyectos, puesto que hay muchas clases de recursos (CPU, memoria, E/S, intercomunicación de procesos, etc.) donde cada tipo es usado de una forma distinta e impredecible. Si hay usuarios en el sistema, existe aún más complejidad y dificultad de prever que va a ocurrir, por lo que ya que alojar los procesos de forma estática es tan complejo que seguramente lleve a que se desperdicien recursos, lo mejor es una asignación dinámica de estos recursos.
Además estos paquetes funcionan a nivel de usuario, como si fueran aplicaciones corrientes, lo que les hacen incapaces de responder a las fluctuaciones de la carga o de otros recursos o de adaptar la carga entre los distintos nodos que participan en el cluster. En cambio openMosix funciona a nivel de kernel por tanto puede conseguir toda la información que necesite para decidir cómo está de cargado un sistema y qué pasos se deben seguir para aumentar el rendimiento, además puede realizar más funciones que cualquier aplicación a nivel de usuario, por ejemplo puede migrar procesos, lo que necesita una modificación de las estructuras del kernel.
A fecha de junio de 2001 la lista demostraba claramente como estaban avanzando los supercomputadores, algunos datos curiosos fueron: