 nodos que
conforman el cluster.
nodos que
conforman el cluster.
nodos que
conforman el cluster.
Luego los ![]() recursos que posee un nodo
recursos que posee un nodo ![]() cualquiera se identificaran por el conjunto
cualquiera se identificaran por el conjunto ![]() de esta forma:
de esta forma:
Esto permite ver a cada nodo como un cúmulo de recursos, dispuestos para ser utilizados por el cluster. por lo tanto, extrapolando conceptos, un cluster no deja de ser también una conjunción de recursos, así
Un nodo puede tener muchos recursos a la vez: procesador, memoria, targetas PCI, dispositivos de E/S, etc.. Sin embargo no es ahora tan importante saber cuantos recursos gestiona openMosix sino cómo lo hace. Esto es, ¿cómo se llega a la ponderación de cada nodo?
Antes de responder es importante apuntar lo que debiera haberse comprendido en la sección anterior: openMosix basa sus decisiones de migración en una algorítmica basada en modelos económicos, donde los recursos estan ponderados en una misma escala para simplificar los cálculos. Estos cálculos deben ser computables en el menor intervalo de tiempo posible para dotar al sistema de la máxima adaptabilidad a las condiciones cambiantes que los usuarios -los procesos en última instancia- puedan propiciar.
No se entrará -por el momento- en averiguar cómo se equiparan parámetros tan
dispares como velocidad de procesamiento o cantidad de memoria. Lo relevante ahora es ver qué permite hacer esta
asignación. Se supondrá, para cualquier nodo ![]() :
:
Igualmente interesa poder estimar los recursos que necesitarán las distintas
tareas ![]() , de cara a predecir el nodo donde se ejecutarían con más
celeridad. Así se definen para las tareas cuatro parámetros.
, de cara a predecir el nodo donde se ejecutarían con más
celeridad. Así se definen para las tareas cuatro parámetros.
Se asume, para una algorítmica no ideal -y por tanto suponiéndose implementable- que
![]() y
y ![]() son conocidos y
son conocidos y ![]() es desconocido en
es desconocido en ![]() .
.
La finalidad de la definición de los parámetros que hasta ahora se han
visto es poder decidir diversos aspectos que conciernen a la migración de
procesos -en última instancia, el objetivo de openMosix-: decisiones sobre
qué proceso migrar y dónde hacerlo se apoyan precisamente en
los parámetros vistos. Esto es, para definir qué proceso deberá migrarse
deben medirse los recursos -y la cantidad de ellos- que ocupará en el nodo
que lo hospede. Igualmente para saber qué nodo es el mejor para aceptar dicho proceso
deberá medirse la carga computacional de un cierto número de ellos para saber
cual dispone de mayor cantidad de ella y, en consecuencia, cual será capaz de
retornar el resultado de proceso en el menor tiempo posible.
El poder computacional de un nodo queda definido no solamente por la ponderación de sus recursos, sino por la utilización de ellos tanto en el actual instante como en el futuro que venga marcado por la planificación de tal recurso.
Debería definirse la carga de un nodo. Esto es para un nodo ![]() en el
instante
en el
instante 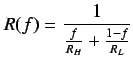 :
:
.
Análogamente, la carga de un nodo se mide en función de los recursos de que ya no dispone. En este caso se han dado las expresiones para procesador y memoria.
No obstante para medir la carga de un nodo openMosix no utiliza solamente esta aproximación. Hay condiciones que pueden desajustar notablemente los valores para la carga calculada y la carga real, mayormente cuando el nodo hace swapping.
La implemenación de openMosix soluciona este apartado sirviéndose de un parámetro
 , que se convertirá en un factor que multiplicará a la expresión de
carga del nodo y que por tanto sobredimensionará el valor calculado tras el
repaso de la ponderación de recursos. Esto tiene una completa lógica ya
que con acceso a swap el procesador tiene que utilizar muchos más ciclos que trabajando
con memoria, para recuperar una página.
, que se convertirá en un factor que multiplicará a la expresión de
carga del nodo y que por tanto sobredimensionará el valor calculado tras el
repaso de la ponderación de recursos. Esto tiene una completa lógica ya
que con acceso a swap el procesador tiene que utilizar muchos más ciclos que trabajando
con memoria, para recuperar una página.
Para formalizar esta idea puede escribirse:
OBJETIVO DE RENDIMIENTO DE OPENMOSIX
El objetivo de los cálculos de openMosix es optimizar el aprovechamiento de la
totalidad de los recursos del sistema. Así por ejemplo, para cada nuevo proceso
iniciado no se estudia solamente el aumento de carga en el nodo local, sino que se tiene en cuenta el
contexto de carga de todo el sistema.
Cuando existen suficientes procesadores en el cluster para encargarse de su
carga, cada proceso se servirá al procesador menos cargado
y se devolverá la respuesta tan rápido como pueda hacerlo.
Si por el contrario no existen suficientes procesadores para encargarse de los procesos pendientes de ejecución, se evaluará el tiempo de ejecución para un nodo y para el resto de los nodos. De esta manera se llega a un completo estudio sobre el impacto del aumento de carga que éste propicia al sistema, para luego decidir cual es el mejor nodo de ejecución. Antes de ver esto se define:
Se deduce que la carga total de todos los procesadores del cluster será
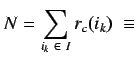 . Si la carga para cualquier nodo es
. Si la carga para cualquier nodo es ![]() , la carga de los restantes es
, la carga de los restantes es
![]() . La carga :
. La carga :
La pérdida de tiempo comparativa para la ejecución de los ![]() procesos en función de estas dos situaciones se puede expresar como:
procesos en función de estas dos situaciones se puede expresar como:
![]() .
.
La algorítmica de openMosix intentará minimizar esta pérdida.
Pero la algorítmica utilizada depende enormementede la topología de los nodos el cluster, es decir, no supone el mismo esfuerzo computacional hacer los cálculos sobre efectos de carga para un conjunto de máquinas iguales6.3 -donde la carga repercutirá numéricamente igual y por lo tanto solo será necesario hacer la predicción una vez- que para un conjunto de máquinas donde la carga supone una sobrecarga distina.
Esta situación debe tenerse en cuenta, y se modeliza de la siguiente forma:
![]() .
.
![$ \displaystyle RELACIONADOS= \{\ \left[ R(i_a),R(i_b) \right] \ \vert \
R(i_a)...
... \neq
r_c(i_b)\vee r_m(i_a)\neq r_m(i_b)\ \} \Rightarrow\ c(j,i_a)\neq c(j,i_b)$](img109.png) .
.
![]() .
.
Dadas estas diferentes situaciones podrá darse un algoritmo para resolver la planificación en cada una de ellas, y como se ha apuntado se medirá su ratio de competencia con el algoritmo óptimo. Por lo tanto van a compararse.
Un algoritmo que se ejecuta a la vez que los procesos -a tiempo real- es
competitivo de grado ![]() si para una secuencia de entrada
si para una secuencia de entrada ![]() ,
,
![]() , siendo
, siendo ![]() una constante
definida y
una constante
definida y ![]() el algoritmo ideal que no se calcula.
el algoritmo ideal que no se calcula.
Esta expresión toma diferentes valores para ![]() dependiendo del algoritmo
utilizado para resolver la planificación, y dicha planificación depende de
la topología del cluster que anteriormente ya se ha clasificado. Esta clasificación imprime diferencias a diferentes niveles. El más
immediato, como se ha citado, es en la decidibilidad del algoritmo de
migración. El grado de competición
dependiendo del algoritmo
utilizado para resolver la planificación, y dicha planificación depende de
la topología del cluster que anteriormente ya se ha clasificado. Esta clasificación imprime diferencias a diferentes niveles. El más
immediato, como se ha citado, es en la decidibilidad del algoritmo de
migración. El grado de competición ![]() según la topología se define:
según la topología se define:
. Esto se debe a que en
este caso hay que tener en cuenta muchas variables que en los demás casos
podían obviarse.
Existe no obstante el algoritmo Assign-U pensado especialmente para máquinas que no tienen relación entre sí para trabajos que se mantienen en un mismo nodo, basado en una función exponencial para el coste de un nodo en particular para una carga dada. Este algoritmo asigna cada trabajo a uno de los nodos para minimizar el coste total de todos los nodos del cluster. Este algoritmo es:
![]() ,
donde
,
donde
Como se puede ver, la formula favorece a los nodos que tienen cargas menores.
Por ejemplo supongamos que tenemos 2 nodos, uno de ellos con una carga 5 y otro nodo
con una carga 10.
En esta configuración hemos decidido que el parámetro ![]() tenga un
valor de 2 (para simplificar nuestros cálculos).
Se inicia un nuevo trabajo que añade una carga de 1.
Para nuestros dos nodos tenemos:
tenga un
valor de 2 (para simplificar nuestros cálculos).
Se inicia un nuevo trabajo que añade una carga de 1.
Para nuestros dos nodos tenemos:
![]() ,
,
![]() .
.
Claramente el primer valor que corresponde al nodo con menor carga (5) minimiza
la carga del sistema por lo tanto se elegirá el primer nodo como nodo
destinatario del nuevo proceso.
Las cargas de los nodos se ponderan en potencias de base 2 -gracias a
![]() - y esto permite agrupar los nodos con cargas iguales. La resolución
del nodo con menor carga final puede calcularse a aprtir de un árbol binario.
Este algoritmo es competitivo de grado
- y esto permite agrupar los nodos con cargas iguales. La resolución
del nodo con menor carga final puede calcularse a aprtir de un árbol binario.
Este algoritmo es competitivo de grado
![]() , para máquinas no relacionadas
y trabajos permanentes.
, para máquinas no relacionadas
y trabajos permanentes.
Se puede extender este algoritmo y el ratio de competitividad a los trabajos
que migran usando como máximo
![]() migraciones por trabajo.
Para este nuevo tipo de situación necesitamos un parámetro más
migraciones por trabajo.
Para este nuevo tipo de situación necesitamos un parámetro más ![]() que es la carga de un nodo
que es la carga de un nodo ![]() justo antes de que
justo antes de que ![]() haya sido por última
vez asignado a
haya sido por última
vez asignado a ![]() . Cuando un trabajo ha finalizado, este algoritmo comprueba la estabilidad
del sistema para cada trabajo
. Cuando un trabajo ha finalizado, este algoritmo comprueba la estabilidad
del sistema para cada trabajo ![]() en cada nodo
en cada nodo ![]() . Esta es una condición
de estabilidad que siendo
. Esta es una condición
de estabilidad que siendo ![]() el nodo donde el trabajo
el nodo donde el trabajo ![]() está
actualmente, se definde como:
está
actualmente, se definde como:
![]()
Si esta condición no es satisfecha por algún trabajo, el algoritmo reasigna
el trabajo que no satisface la condición a un nodo ![]() que minimiza
que minimiza
![]() .
.
Esta fórmula es quizás más omplicada de ver que las demás. Se detallan seguidamente sus factores:
Entre las reflexiones que pueden sacarse de este estudio se encuentra la
explicación a la clara tendencia a construir clusters con nodos
idénticos o con las mínimas diferencias entre nodos. El rendimiento
será mucho más generoso.
Se define también una secuencia de llegada de peticiones, en tiempos arbitrarios, que como puede preverse son los procesos que llegan a un nodo -localmente por el usuario o desde un remoto- para ser ejecutados. Véase cada elemento con más detalle.
A cada arco -físicamente un enlace de red- se le asocia cierta ponderación que irá en
aumento cada vez que se genere una comunicación sirviéndose de él. Esta
situación se produce cada vez que un proceso crea un nexo entre su remote y su deputy, puesto que ambas partes deben permanecer
continuamente comunicadas. Al referirse a un canal real de comunicación, es
necesario asociarles una capacidad -ancho de banda-, sea ![]() .
.
La petición producida por la tarea ![]() que sea asignada a un camino -conjunto de arcos por los que
circulará la petición- desde una fuente
que sea asignada a un camino -conjunto de arcos por los que
circulará la petición- desde una fuente ![]() a un destino
a un destino ![]() disminuye la capacidad
disminuye la capacidad
![]() en cada uno de los arcos que pertenecen a este camino en una cantidad
en cada uno de los arcos que pertenecen a este camino en una cantidad
![]() .
El objetivo es minimizar la congestión
.
El objetivo es minimizar la congestión ![]() máxima de cada uno de los enlaces,
que es el ratio entre el ancho de banda requerido de un enlace y su capacidad:
máxima de cada uno de los enlaces,
que es el ratio entre el ancho de banda requerido de un enlace y su capacidad:
La solución viene dada por la minimización del máximo uso de procesador y memoria. Tras
ello puede ser reducida a un algoritmo -en tiempo de ejecución- del problema de encaminamiento de
los circuitos virtuales. Esta reducción funciona como sigue:
 .
.
Esta política acota la congestión máxima del enlace al valor máximo entre la máxima carga de procesador y el máximo uso de la memoria. De esta manera se extiende para solucionar el problema del encaminamiento.
Este algoritmo es competitivo de grado
![]() .
Por reducción, produce un algoritmo para manejar recursos heterogéneos
que es competitivo también de grado
.
Por reducción, produce un algoritmo para manejar recursos heterogéneos
que es competitivo también de grado
![]() en su máximo uso de cada recurso.
Queda claro que cuando se escoge un camino se está realmente eligiendo un
nodo y que las diferencias entre los dos problemas se solucionan por la
función que mapea la carga de los enlaces de uno de los problemas con la
carga de los recursos del otro problema.
Esto hace que la forma de extender sea muy simple porque lo único que es necesario
para tener en cuenta un recurso más en el sistema es añadir un arco,
además de una función que mapee el problema de
ese recurso en particular en el problema de encaminamiento de circuitos
virtuales.
en su máximo uso de cada recurso.
Queda claro que cuando se escoge un camino se está realmente eligiendo un
nodo y que las diferencias entre los dos problemas se solucionan por la
función que mapea la carga de los enlaces de uno de los problemas con la
carga de los recursos del otro problema.
Esto hace que la forma de extender sea muy simple porque lo único que es necesario
para tener en cuenta un recurso más en el sistema es añadir un arco,
además de una función que mapee el problema de
ese recurso en particular en el problema de encaminamiento de circuitos
virtuales.
La ponderación para un nodo ![]() , poseedor de
, poseedor de ![]() recursos
consiste en una expresión que relaciona el número total de
nodos del cluster con la utilización de cada recurso.
La elección de los parámetros parece correcta -ha sido elegida por los
desarrolladores- puesto que la parte de potencia que un nodo significa en el
seno de un clsuter depende del número de nodos existentes. De igual forma
un nodo potente no servirá de mucho si tiene todos sus recursos utilizados.
recursos
consiste en una expresión que relaciona el número total de
nodos del cluster con la utilización de cada recurso.
La elección de los parámetros parece correcta -ha sido elegida por los
desarrolladores- puesto que la parte de potencia que un nodo significa en el
seno de un clsuter depende del número de nodos existentes. De igual forma
un nodo potente no servirá de mucho si tiene todos sus recursos utilizados.
La expresión que se indica tendría la forma:
![]() , donde
, donde
![]() marca la utilización del recurso
marca la utilización del recurso 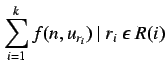 .
.
Particularmente esta función de relación entre los parámetros indicados
tiene la forma:
![]() ,
donde se relaciona para cada recurso su uso actual con su uso
máximo6.4.
,
donde se relaciona para cada recurso su uso actual con su uso
máximo6.4.
NOTA: Tras estudios experimentales se ha probado que el algoritmo consegue una máxima pérdida
de rendimiento dentro de
![]() de la máxima pérdida de rendimiento del
algoritmo óptimo.
de la máxima pérdida de rendimiento del
algoritmo óptimo.
Esta relación entre los usos de memoria funciona tal cual para el recurso de memoria.
El coste por una cierta cantidad de uso de memoria en un nodo es
proporcional a la utilización de memoria -relación memoria usada/memoria
total-.
Para el recurso procesador se debería saber cuál es la máxima carga
posible, esto no es tan sencillo como con la memoria y va a ser necesario tener que
hacer algún manejo matemático.
Se asume que ![]() es el entero más pequeño en potencia de dos, mayor
que la mayor carga que se haya visto hasta el momento, y que este número es la carga máxima posible.
Aunque esta aproximación no sea realmente cierta sirve perfectamente para
resolver el problema.
es el entero más pequeño en potencia de dos, mayor
que la mayor carga que se haya visto hasta el momento, y que este número es la carga máxima posible.
Aunque esta aproximación no sea realmente cierta sirve perfectamente para
resolver el problema.
Tras estas aclaraciones las particularizaciones de ponderación para el tipo de recurso procesador y memoria quedaría respectivamente:
memoria
![]()
y procesador
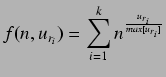 .
.