| Siguiente: Conclusiones. Superior: Proyecto AAGRAFA. Anterior: Captura de datos. |
Como habíamos dicho anteriormente, a lo largo del desarrollo del proyecto se ha contemplado separadamente la captura digital de la distribución del resultado final. Hasta ahora, hemos hablado de los principales trabajos de captura en los que se trabaja actualmente, pero es en la parte del procesado la de información dónde Linux se ha mostrado como una herramienta fundamental.
Todas las tareas descritas anteriormente son completamente dependientes de elementos de hardware para los que Linux hoy por hoy no ofrece el ``soporte'' necesario. Por ello, todos los equipos destinados a captura digital están equipados con sistemas operativos de Microsoft, principalmente Windows NT 4.0 Siendo simplistas, por lo único que se usan estos equipos es porque disponen de los controladores necesarios para los escáneres, en su mayoría equipos de gama profesional para los que desde Linux no funciona ninguna clase de controlador genérico.
Sin embargo, en la fase de tratamiento y distribución de la información, Linux no tiene rival, cubriendo desde el procesado de imágenes en grandes bloques, su almacenamiento y catalogación, y su distribución posterior a través de un servidor web. Pero veamos esto un poco más despacio.
El camino que siguen las imágenes desde su captura es el siguiente: tanto las diapositivas como los negativos de formato medio (6x6) son ``escaneadas'' en máquinas con Windows NT. El siguiente paso, en bloques grandes de imágenes, es tratamiento de todas ellas mediante una macro de Photoshop, que les aplica un filtro de enfoque, un ajuste automático de niveles, una marca de agua, se guarda una copia en formato TIFF y otra reducida en formato jpg. De esta manera, se obtiene un original en TIFF a alta resolución y una copia en jpg, con un tamaño que oscila entre los 100 y 300KB, más apto para su distribución por internet (al menos en los tiempos que corren).
Todo al paso por estos filtros, se podría hacer actualmente utilizando software libre como GIMP (http://www.gimp.org), pero en el momento de comenzar a hacerlas el desarrollo de GIMP no era tan avanzado como ahora, y el sistema de macros de Photoshop, tanto entonces como ahora, es más sencillo y manejable que el de GIMP.
A partir de aquí, todo el tratamiento de imágenes se hace con Linux. Los originales en TIFF se guardan en CD-ROM y las imágenes jpg se pasan a una máquina Linux, bien a través de samba, bien a través de ftp.Una vez allí se procesan con una serie de shell scripts escritos en bash. El primero de estos scripts coloca el sello de la ETSAM en la esquina inferior derecha de cada imagen, siempre a la misma distancia del borde. Esto, que es una operación trivial, fue del todo imposible hacerla con Photoshop, pues carece de herramientas para colocar una imagen sobre otra en una determinada posición. Sin embargo, con un breve script que llama a identify y a combine, ambos parte del paquete imagemagick (gran paquete para el tratamiento de imágenes, por cierto) se resuelve de manera óptima.
Posteriormente, otro par de scripts crean una serie de paginas web, dividiendo cada directorio que contiene imágenes y generando páginas web con índices sencillos para que puedan ver con comodidad. Actualmente, las imágenes se muestran en bruto, sin más catalogación que la división en subdirectorios, pero se está trabajando en un sistema de catalogación y consulta del que hablaremos a continuación. Estas imágenes se cuelgan automáticamente del servidor del proyecto http://www.aagrafa.aq.upm.es
Aunque lo anterior puede ser un buen ejemplo de como automatizar el procesado de grandes cantidades de información, la parte importante de Linux en el Proyecto Aagrafa es el soporte para la base de datos que cataloga toda la información. A final, la idea de todoe esto es hacer accesible todo lo que podamos del extenso fondo documental de la Escuela, tanto de la blblioteca como de los distintos profesores y Departamentos. De cara al usuario final, todo esto se presenta mediante un buscador en una página WEB. Evidentemente, el servidor es una máquina linux con Apache 1.3.9 (http://www.apache.org).
Actualmente, tenemos el trabajo dividido en dos líneas; el interfaz de consulta, vía páginas web, y el programa de catalogación de contenidos. Para el desarrollo de la aplicación de consulta, el modelo que hemos elegido es clásico en internet entre las aplicaciones que hacen consultas a bastes de datos: un interfaz web, que llama a CGI's en perl, que resuelven la consulta y genera una página como resultado. Para lo segundo. estamos desarrollando una aplicación en java, pero vayamos por partes.
El motor de base de datos que empleamos es Postgres 6.5 (http://www.postgresql.org), sobre una Debian Potato. Este es un motor ampliamente conocido en el mundo del software libre, y aunque no es el más rápido, su seguidores son legión, por lo que no es difícil encontrar voluntarios que den ``soporte'' cuando surge alguna duda.
El diseño de la base de datos está basado en objetos o elementos arquitectónicos, a los cuales se les asignan propiedades, palabras claves que los identifican. Estas palabras, se organizan de un modo abstracto, como calificadores sueltos, a los que a su vez se califican con un ``tipo de calificador''. De esta forma, cada elemento (objeto) arquitectónico puede tener asignadas n parejas de elementos calificador-tipo calificador. Así, se consigue una gran abstracción respecto de la clasificación de los contenidos, estado basada esta no en palabras clave, sino en relaciones.
Por otro lado, los objetos arquitectónicos pueden ser padres y/o hijos de otros objetos, definiendo relaciones jerárquicas que pueden ser incorporadas a las búsquedas.
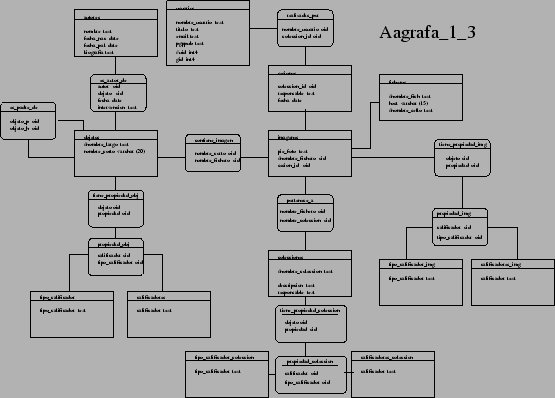
En este contexto, la imágenes son de alguna manera ``propiedades'' de los objetos, y no al revés. Así, las búsquedas se hacen por parámetros que califican a los objetos como tales, no a las imágenes. Pongamos un ejemplo: un objeto puede ser la Catedral de Santiago de Compostela. Podría tener asociados calificadores como ``piedra'' o ``románico''. Estos calificadores se relacionan con los objetos según un tipo de calificador; en el caso de ``piedra'' podría ser ``tipología'' o ``material''. Con este esquema se puede discriminar en las búsquedas por el tipo de calificador. Si quisiéramos encontrar todos los objetos construidos en piedra, la búsqueda sería por el calificador ``piedra'', y el tipo de calificador, ``material''. Naturalmente, se puede buscar por varios calificadores simultáneamente, o discriminar por varios tipos de calificador, autores, fechas...Todo esto se vé claro en la figura 1. En la figura 2 se puede ver el diseño de toda la base. Como se ve, hay tres tablas principales (a nivel conpectual); la de objetos, la de imágenes y la de colecciones (de imágenes). Cada una de estas tablas se califica por un esquema de cuatro tablas como el descrito más arriba y mostrado en la figura 1.
Al hilo de todo esto, una de las novedades que se ha incluido en nuestro buscador es la posibilidad de hacer búsquedas con operadores lógicos anidados, con cualquier nivel de complejidad. Un ejemplo; se pueden hacer búsquedas del tipo (a|b)+(c|d), y cosas similares. Esto se hace con el módulo perl-byacc. Con esto, lo que se hace es definir el comportamiento de la gramática en formato yacc, y automáticamente se genera una código en perl que se incorpora los CGI's de búsqueda. yacc es una generador de analizadores sintácticos, y genera el código necesario para analizar las condiciones lógicas de la búsqueda. Con el resultado que devuelve el analizador, se construye la consulta SQL que se envía a la base de datos.
En cuanto al lenguaje, como se comentó más arriba se ha elegido perl. perl es muy cómodo para este tipo de aplicaciones, pues el tratamiento de cadenas y expresiones regulares facilitan mucho la creación de filtros y sentencias SQL para consultas a la base de datos. Por otra parte, para perl existen infinidad de módulos para las más variopintas tareas. Un ejemplo es perl-byacc (bueno, realmente no es un módulo para perl como tal, sino una utilidad que genera código en perl a partir de una gramática yacc). Otra ventaja que tiene perl es la facilidad para crear clases al estilo de C++ (salvando las distancias). Además, al ser código interpretado, no necesita compilarse cada vez, lo que acelera enormemente el desarrollo. El ser interpretado, es quizá la mayor desventaja de perl respecto a otros lenguajes como C, ya que su ejecución es más lenta, pero módulos para apache como el mod_perl hacen que se reduzca al mínimo esta desventaja.
Para la conexión a la base de datos, se utiliza la combinación de módulos para perl DBD+DBI. DBI viene a ser como un API genérico de bases de datos. Este módulo (o clase) implementa una serie de métodos para la conexión a bases de datos SQL; La ventaja de usar este módulo, en lugar de librerías (módulos) para Postgres, es que si se respeta el estándar SQL, es fácil cambiar de base de datos reaprovechando todo el código. La conexión propiamente se hace a través del modulo DBD. Este módulo es específico para cada base de datos. Basta con cambiar este módulo para cambiar la base de datos. Hay módulos para casi todas las bases de datos conocidas de cierto peso; MySQL, Oracle, DB2...
Se puede acceder a una versión de trabajo del buscador en la dirección http://www.aagrafa.aq.upm.es/consulta.html
La otra gran línea de trabajo es el programa de catalogación. Para facilitar la introducción de datos en la base, definición de objetos, calificadores, etc...y no tener que vérnoslas directamente con intragables ristras de SQL, se decidió crear un programa con una interfaz de ventanas familiar al usuario. Para crearlo se escogió el lenguaje Java, dadas sus características de portabilidad entre plataformas, seguridad y facilidad de desarrollo. La comunicación con la base de datos se realizaría mediante JDBC.
En un principio se optó por crear una aplicación independiente, totalmente basada en Java2 (JDK 1.2) y Swing. En el momento en que se comenzó a programar, nos encontramos con el problema de la falta de herramientas RAD que soportasen Java2 en ese momento. Tras una intensiva búsqueda por la red, nos encontramos con una herramienta que lo soportase: NetBeans, programa totalmente escrito en Java2. Dicho programa, aunque comercial, poseía una licencia gratuita para uso personal y académico. Tras diseñar un primer prototipo del programa, se abandonó la herramienta por diversas razones. En primer lugar, una de las promesas de NetBeans era la de crear código Java puro, sin emplear clases propietarias que obligasen a incluirlas en la distribución del programa. No obstante, al crear una ventana el layout manager por omisión era uno particular de NetBeans que había de ser redistribuido, lo que no deja de resultar un poco molesto. Por otra parte, la concordancia entre código escrito y apariencia visual de la aplicación se lograba por el método de marcar, mediante comentarios especiales, partes del código que estaban vedadas a la modificación por parte del usuario, lo cual resulta todavía mas molesto, ya que limita la posibilidad de editar el código con cualquier otro programa que no resulte el propio NetBeans. Dado que en el momento en que estas pegas empezaban a resultar irritantes Borland lanzó al mercado la versión 3 del JBuilder, se optó por reescribir todo el código en JBuilder 3, aprovechando de paso para introducir una serie de mejoras en la estructura del programa, en otras palabras, reescribirlo desde cero para hacerlo bien, una de las ventajas de tener unos plazos de entrega realmente flexibles. De hecho, no estamos realmente seguros de tener plazos de entrega. (Aquí Carlos escribiría ``Una de las ventajas de NO trabajar para Microsoft'').
Los motivos de escoger JBuilder 3 como herramienta de desarrollo son su capacidad de creación de código Java 100% puro (como Sun dice), ésta vez de verdad, la rapidez de su compilador y las herramientas de sincronización de código y representación visual, que no se basan en ningún tipo de marcadores propietarios, lo que da lugar a un código realmente limpio. De hecho, muchas veces se han hecho modificaciones al código con editores de texto normales y corrientes, y, salvo en una ocasión, JBuilder nunca ha tenido problemas en reconocer el código modificado.
La estructura interna del programa fue totalmente remodelada. En un principio existía una clase para la introducción de cada elemento en la base de datos (Objetos, Autores, Calificadores...). Dicha clase incorporaba no solo el código visual y de interacción con el usuario, sino también el código para efectuar consultas SQL, inserción y modificación de datos, etc. Al reescribir el programa, se aboga por un planteamiento modular, tomando como base la arquitectura Modelo-Vista-Controlador (Model-View-Controller), según la cual el programa ha de subdividirse en tres partes interrelacionadas: El Modelo representa una conexión con los datos existentes en la base de datos, es el que almacena y se encarga de gestionar todas las consultas. Es una abstracción de la base de datos, que puede ser comprendida por el código Java. La Vista es el aspecto visual del programa: Se encarga de presentar al usuario los datos del Modelo, de forma razonablemente coherente. El Controlador recibe e interpreta las peticiones del usuario: Clicks del ratón, introducción de datos, etc., se las transmite al Modelo y actualiza la Vista. Como todos los excesos son malos, es práctica habitual unir la Vista y el Controlador en un mismo bloque. Así, el nuevo programa, bautizado pedantemente como AagrafaDBMS2 (DataBase Management System 2, ahí queda eso), al iniciarse establece una conexión con la base de datos y se encarga de llenar de contenido diversas clases que actúan como Modelos, existiendo un Modelo (una clase de Java) por cada tabla de datos de la base de datos. Dichos Modelos están definidos como estáticos, garantizando que únicamente existe una copia de cada uno, lo cual es necesario para mantener la integridad de los datos ante la posibilidad de que existan varios usuarios introduciendo datos simultáneamente ( parte que nunca llegó a programarse pero que fue tenida en cuenta al diseñar el programa). Las ventanas de introducción de datos enlazan con el Modelo, del que obtienen los datos, y le pasan las peticiones de introducción de datos del usuario. El Modelo introduce los datos en la base y realiza todos los enlaces entre tablas necesarios. A continuación actualiza todas las vistas que existan, ésto se efectúa mediante clases que extienden a java.util.Observable y que implementan java.util.Observer. De éste modo la sincronización entre los datos existentes y los presentados es perfecta.
Cuando todo iba viento en popa, un nuevo escollo surgió ante nosotros: El diseño de la base de datos tenía un ligero error que, en determinadas circunstancias muy particulares, podría provocar el almacenamiento erróneo de datos. Como en informática las circunstancias muy particulares se dan con una frecuencia pasmosa, se optó por rehacer la base de datos. Ésto afectó a la parte del código que lidia con el SQL, pero, aprovechando el alto en el camino, volvimos a plantearnos el diseño del programa.
Para que engañarnos: El problema con Java, aparte de la simpática política de Sun, es la necesidad de distribuir el JRE para que los programas funcionen. Además, en ese momento, el tema del JDK para Linux estaba bastante confuso (la mencionada simpática política). Toda la parte de búsqueda y consulta de datos se realizaba mediante Netscape Navigator, así que se pensó que sería una buena idea rehacer el programa de introducción de datos para que funcionase a base de applets desde Navigator, lo cual soluciona el problema de la redistribución de la mejor manera: Eliminándola. Esto planteó otro problema, ya que Navigator no soporta Java2, por lo que hay que andar con mucho cuidadito acerca de los métodos y clases a emplear... afortunadamente podemos usar el modelo de eventos del JDK 1.1. Eso sí, de componentes Swing ni hablar, así que nos vemos constreñidos al AWT. El hecho de basarlo todo en web plantea otros problemas, como la sincronización de datos o la persistencia de la información del usuario (login, password) al ir navegando por las distintas páginas, problemas que, como suele pasar en programación, acabaremos por resolver aunque no se sepa muy bien cómo. El desarrollo en applets ha comenzado hace relativamente poco, pero avanza a buen ritmo dada la facilidad de reaprovechar código genérico escrito con anterioridad.